Exp<-newFit("Exponential", pexp,"rate", list(c(0,1)))
Gam<-newFit("Gamma", pgamma, c("shape","rate"), list(c(0,5), c(0,5)))
Wei<-newFit("Weibull", pweibull, c("shape","scale"), list(c(0,5),c(0,2000)))Elegir un modelo de probabilidad
El modelo paramétrico propuesto para describir el comportamiento de la curva de curva de recuperación de la fluorescencia a partir del momento del fotoblanqueo, es el siguiente:
\[F(t)=f_{min}+\alpha\,(1-f_{min})\,p(t-t_0|\Theta),\] donde \(p\) es una función de distribución acumulada parametrizada por \(\Theta\), \(t_0\) es el tiempo del fotoblanqueo y \(f_{min}\) es el valor mínimo de la fluorescencia después del fotoblanqueo, también se define el valor teórico \(f_{max}\) como el valor máximo que puede alcanzar la fluorescencia después del fotoblanqueo, y está dado por: \[f_{max}= f_{min}+\alpha(1-f_{min}).\]
Puede observarse que la función \(F(t)\) está definida en el intervalo de tiempo \(t\in[t_0, \infty)\). De forma análoga, se define la función \(F^{AB}(t)\) para representar a la curva de recuperación de la fluorescencia después del fotoblanqueo la cual está definida en el intervalo de tiempo \(t\in[0, \infty)\):
\[F^{AB}(t)=f_{min}+\alpha\,(1-f_{min})\,p(t|\Theta).\]
En el apéndice de este documento se puede encontrar más información acerca de la construcción del modelo. Para que el usuario pueda realizar el ajuste paramétrico, para el posterior análisis de datos sus datos, tendrá que ocuparse únicamente de elegir el modelo de probabilidad, \(p\), más adecuado. Mediante la función newFit es posible declarar un nuevo modelo de probabilidad, la función recibe como parámetros el nombre que se le quiera dar al modelo, la función de distribución acumulada, el nombre de los parámetros de la función de probabilidad y una lista con los rangos de valores para dichos parámetros. Para más detalles ir a newFit.
Uno de los criterios más importantes para elegir entre distintos modelos de probabilidad es mediante el error medio cuadrático, aquellos modelos que tengan menor error deben ser mayormente preferidos. El error medio cuadrático está dado por la siguiente expresión: \[E_i =\frac{1}{m_i}\sum_{j=1}^{m_i} \left[f_i(t_j)-F(t_j)\right]^2,\] donde \(\{f_1,..,f_n\}\) es un grupo de datos fluorescencia y \(\{t_1,t_2,\cdots,t_{m_i}\}\) son todos aquellos valores mayores al tiempo de fotoblanqueo cuantificados para \(f_i\). La función compareFit comparar el error medio cuadrático de diferentes modelos de probabilidad ajustados a un grupo de datos, por medio de una gráfica Q-Q y el histograma del error de cada uno de los modelos. La función recibe como parámetros al grupo de datos en cuestión, una lista de los modelos que se requieran comparar, así como una serie de parámetros que permiten personalizar el gráfico. Para más detalles ir a compareFit.
compareFit(B, fit=l(Exp, Gam, Wei), col.lines=c("red","yellow"), lty.lines=c(2,1), lwd.lines=2, lwd.mean=2)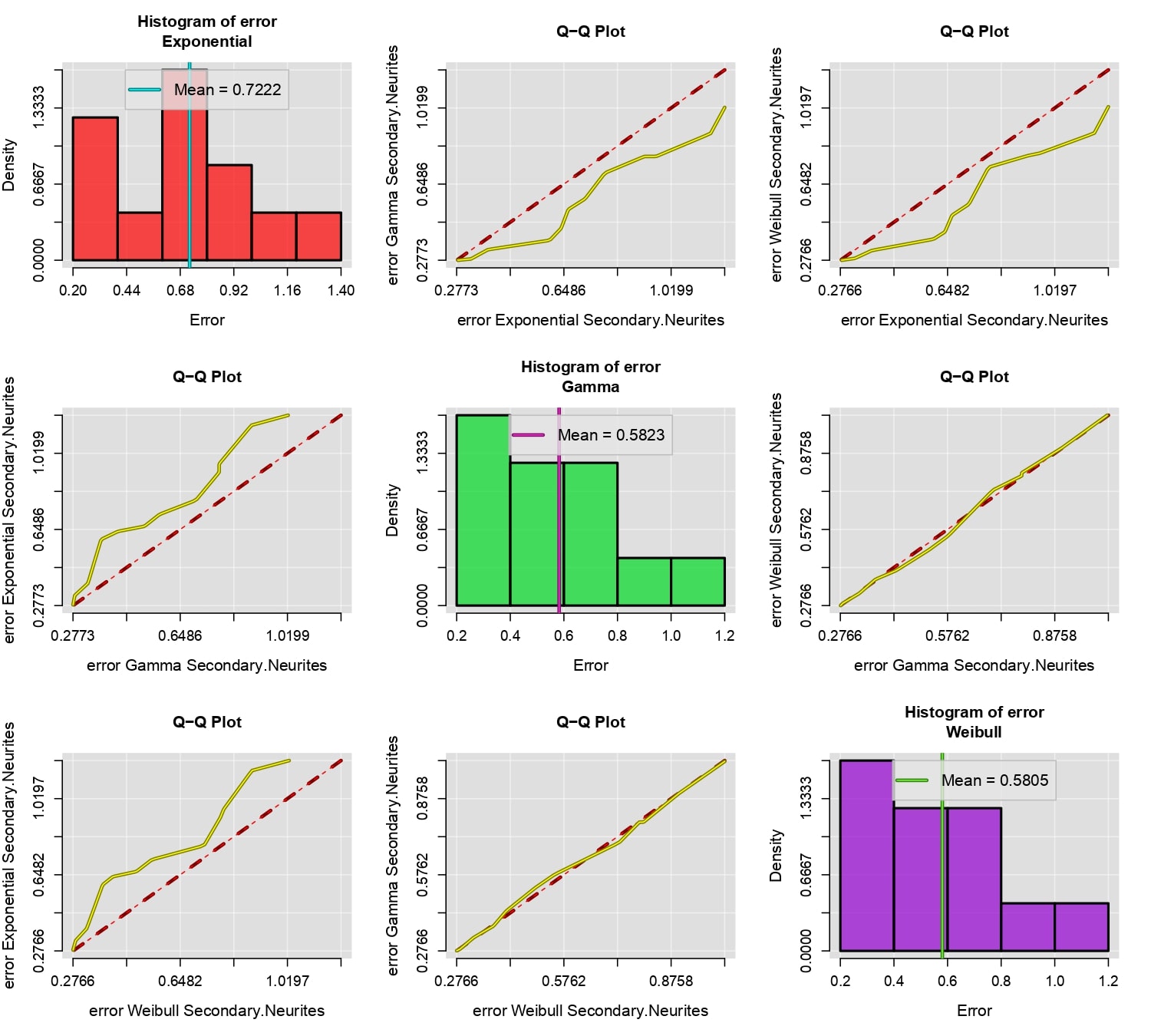
compareFit(C, fit=l(Exp, Gam, Wei), col.lines=c("red","yellow"), lty.lines=c(2,1), lwd.lines=2, lwd.mean=2)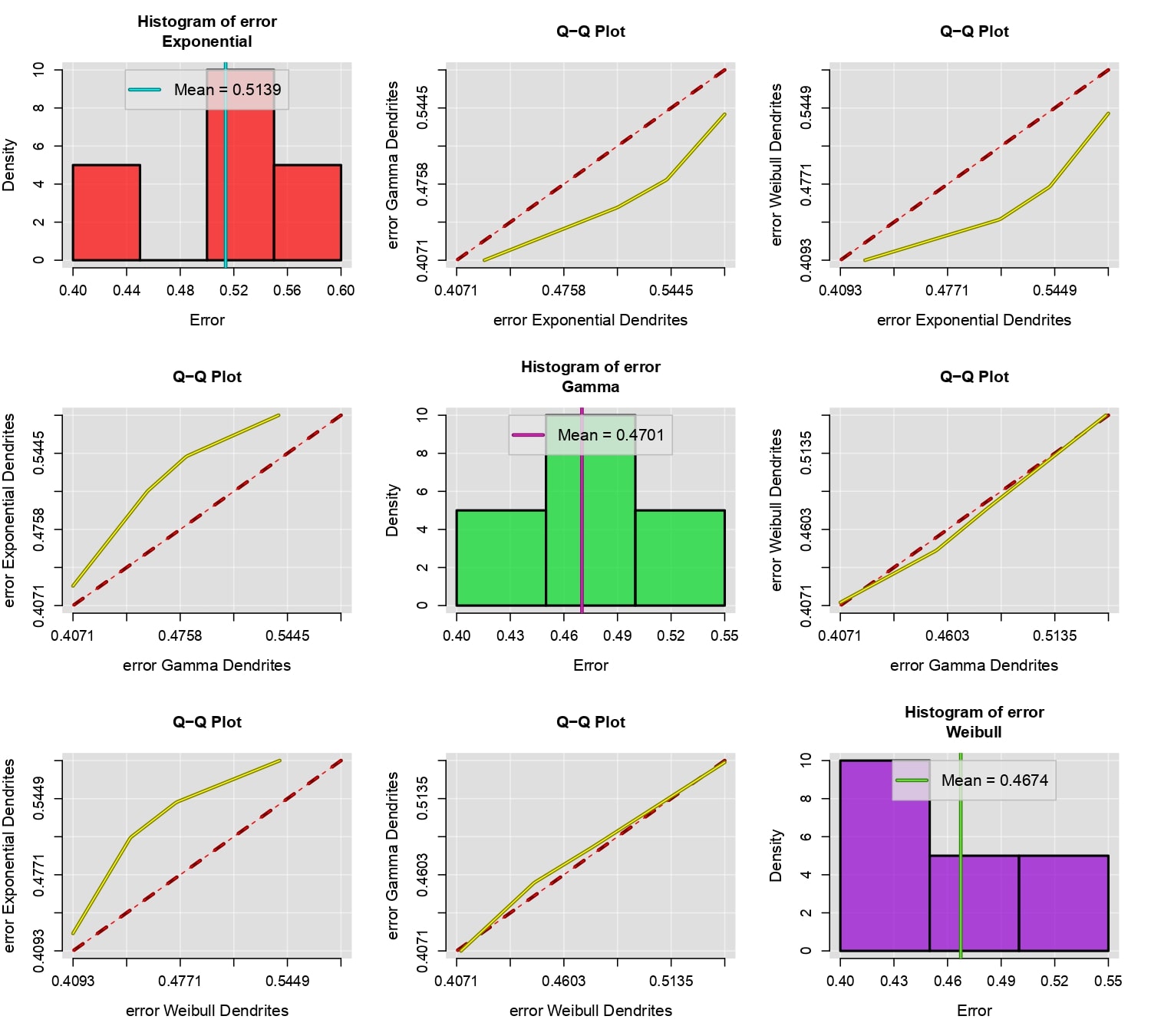
Para más información acerca de la elección de un buen modelo de probabilidad ir al apéndice.