ppareto <- function(t, shape, scale){
ppar <- NULL
for (t in t)
ppar <- c(ppar, 1-(scale/(t+scale))^shape)
ppar
}
Par <- newFit("Pareto", ppareto, c("shape","scale"), list(c(0,a), c(0,b)))Apéndice
El modelo de recuperación de fluorescencia
La cuantificación de la fluorescencia en el proceso de la técnica de FRAP sigue un patrón específico de recuperación. Inicialmente, la fluorescencia se mantiene constante, pero al momento del fotoblanqueo (también conocido como \(t_0\)), la intensidad de la fluorescencia disminuye hasta alcanzar un valor mínimo denominado \(f_{min}\). A partir de ese punto, se inicia un proceso gradual de recuperación de la fluorescencia que se caracteriza por dos condiciones fundamentales: en primer lugar, la recuperación no disminuye a medida que transcurre el tiempo, y en segundo lugar, la fluorescencia alcanza un límite máximo (\(f_{max}\)) que no puede superar el valor inicial antes del fotoblanqueo. Esta evolución se representa de manera gráfica para una mejor comprensión del proceso.
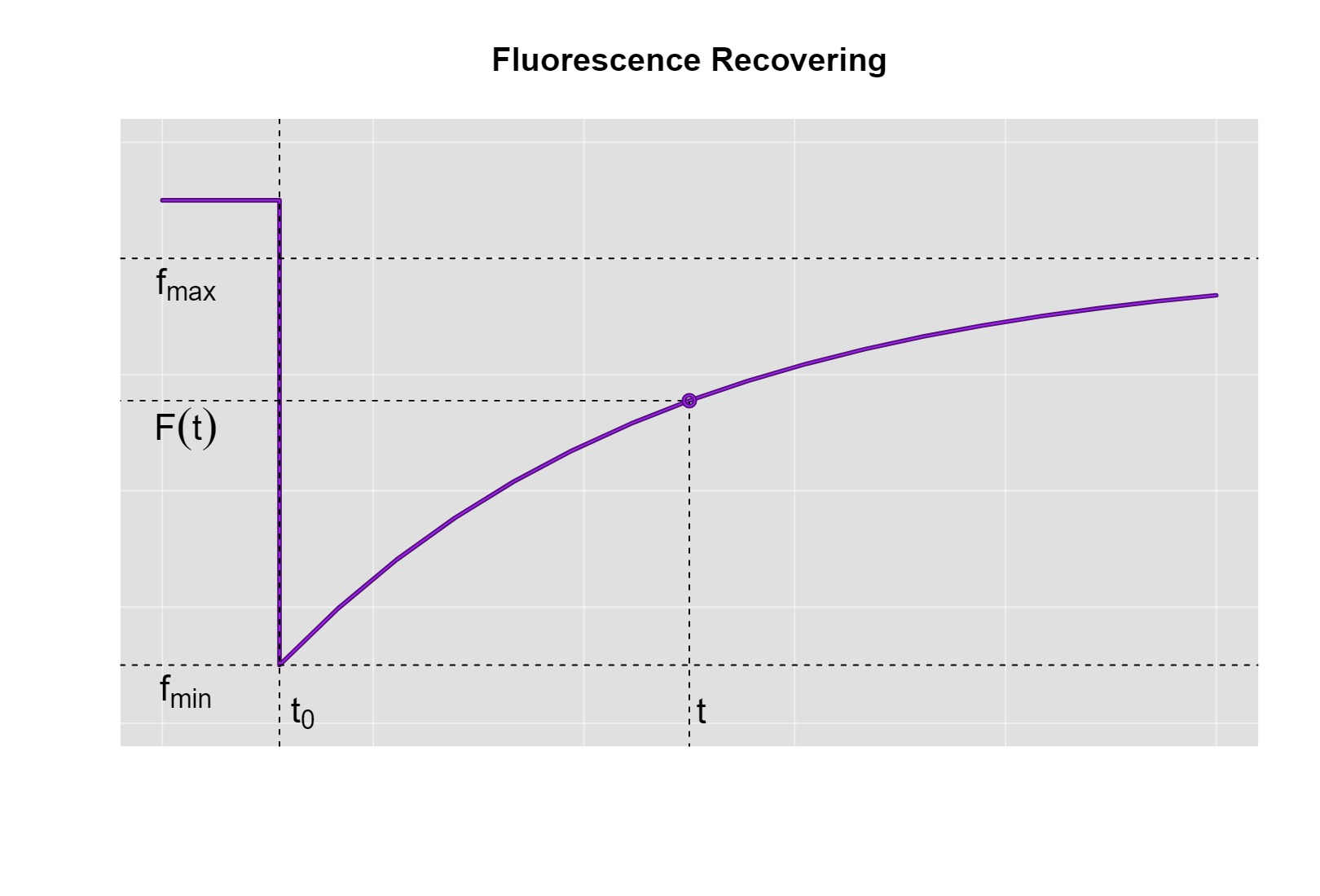
En ese sentido, el modelo propuesto para la recuperación de la fluorescencia debe cumplir con las características anteriores, el modelo general para la recuperación de la fluorescencia después del fotoblanqueo es el siguiente:
\[F(t)=f_{min}+\alpha\,(1-f_{min})\,p(t-t_0|\Theta)\]
En donde \(p\) es una función de distribución acumulada continua (CDF), parametrizada por \(\Theta\).
Observaciones
La función \(F(t)\) está definida en el intervalo \([t_0,\infty)\)
El valor \(f_{max}\) está dado por \[f_{max} =\lim_{t\to\infty}F(t)\]
El valor \(\alpha\) está acotado por los valores \[\alpha\in[0,1]\]
La función de distribución acumulada \(p\) debe estar asociada a una variable aleatoria que con soporte en \((0,\infty)\), recuerde que la CDF se define de la siguiente manera:
\[p(t|\Theta)=\int_0^td(x|\Theta)\,\mbox{d}x\] donde \(d\) es una función de densidad paramétrica.
De forma análoga, se define la función \(F^{AB}(t)\) para representar a la curva de recuperación de la fluorescencia después del fotoblanqueo la cual está definida en el intervalo de tiempo \(t\in[0, \infty)\):
\[F^{AB}(t)=f_{min}+\alpha\,(1-f_{min})\,p(t|\Theta).\]
Probemos que \(F\) cumple con las características de la recuperación de la fluorescencia después del fotoblanqueo:
\(F(t_0)=f_{min}\)
Se evalua
\[\begin{aligned} F(t_0) &=f_{min}+\alpha\,(1-f_{min})\,p(t_0-t_0|\Theta)\\ &=f_{min}+\alpha\,(1-f_{min})\,p(0|\Theta)\\ &=f_{min}+\alpha\,(1-f_{min})\int_0^0d(x|\Theta)\,\mbox{d}x\\ &=f_{min}+\alpha\,(1-f_{min})\,(0)\\ &=f_{min} \end{aligned}\] \[\therefore F(t_0)=f_{min}\]
\(F(t)\) es no decreciente
Considere a \(t_1,t_2\in\mathbb R^+\) tales que \(t_1\leq t_2\), entonces
\[\begin{aligned} t_1-t_0\leq &\;t_2-t_0\\ \Rightarrow p(t_1-t_0|\Theta)\leq &\;p(t_2-t_0|\Theta)\\ f_{min}+\alpha\,(1-f_{min})\,p(t_1-t_0|\Theta)\leq &\;f_{min}+\alpha\,(1-f_{min})\,p(t_2-t_0|\Theta) \end{aligned}\] \[\therefore F(t_1)\leq F(t_2)\]
Lo anterior prueba que el modelo paramétrico \(F\) es no decreciente a lo largo del tiempo.
\(f_{max}=f_{min}+\alpha\,(1-f_{min})\) y \(f_{max}\in[f_{min}, 1]\)
Se calcula el límite de \(F(t)\) cuando \(t\) tiende a infinito:
\[\begin{aligned} f_{max}=\lim_{t\to\infty}F(t) &=\lim_{t\to\infty}f_{min}+\alpha\,(1-f_{min})\,p(t-t_0|\Theta)\\ &=f_{min}+\alpha\,(1-f_{min})\lim_{t\to\infty}\,p(t-t_0|\Theta)\\ &=f_{min}+\alpha\,(1-f_{min})\lim_{t\to\infty}\int_0^{t-t_0}d(x|\Theta)\,\mbox{d}x\\ &=f_{min}+\alpha\,(1-f_{min})\int_0^{\infty}d(x|\Theta)\,\mbox{d}x\\ &= f_{min}+\alpha\,(1-f_{min})\,(1) \end{aligned}\]
\[\therefore f_{max}=f_{min}+\alpha\,(1-f_{min})\] Por otro lado se tiene que \(\alpha\in[0,1]\), entonces
\[\begin{aligned} &0\leq \alpha\leq 1\\ \Rightarrow &0\leq \alpha\,(1-f_{min})\leq 1-f_{min}\\ \Rightarrow &f_{min}\leq f_{min}+\alpha\,(1-f_{min})\leq f_{min}+1-f_{min}\\ \Rightarrow &f_{min}\leq f_{min}+\alpha\,(1-f_{min})\leq 1\\ \Rightarrow &f_{min}\leq f_{max}\leq 1\\ \end{aligned}\] \[\therefore f_{max}\in[f_{min},1]\]
Dados un conjunto de datos de fluorescencia \(f\) y una función de distribución acumulada \(p(\bullet|\Theta)\), entonces los parámetros \((\alpha,\Theta)\) son estimados por medio del metodo de mínimos cuadrados, que consiste en minimizar el error medio cuadrático producido entre las curvas \(f\) y \(F\), la función del error medio cuadrático es la siguiente:
\[\begin{aligned}E(\alpha,\Theta)&=\sum_{j=1}^m\left[f(t_j)-F(t_j)\right]^2\\&=\sum_{j=1}^m\left[f(t_j)-f_{min}-\alpha\,(1-f_{min})\,p(t_j-t_0|\Theta)\right]^2\end{aligned}\] donde \(\{t_1,t_2,\cdots,t_m\}\) son todos aquellos tiempos mayores a \(t_0\) cuantificados para \(f\).
Elegir un modelo de probabilidad
La función de distribución acumulada \(p(t|\Theta)\) es la base para construir el modelo paramétrico de recuperación de la fluorescencia \(F(t|\Theta)\). La elección de la función \(p\) queda a libre criterio del usuario, sin embargo, es indispensable que \(p\) tenga soporte en \((0,\infty)\), otro aspecto del que debe encargarse el usuario es la asignación de los intervalos donde toman valores los parámetros \(\Theta\), esto se logra por medio de la función newFit.
Ejemplo:
Suponga que el usuario ha decidido utilizar una función de probabilidad Pareto, entonces \[p(t|\,\mbox{shape},\mbox{scale})=1-\left(\frac{\mbox{scale}}{t+\mbox{scale}}\right)^{\mbox{shape}}\] \[t>0,\;\;\mbox{scale}>0\;\;\&\;\;\mbox{shape}>0\] Se implementa la función de distribución acumulada Pareto y se declara su ajuste paramétrico asociado:
El código anterior establece que \(\mbox{shape}\in(0,a)\) y \(\mbox{scale}\in(0,b)\). Después de ajustar el modelo Par a un grupo de datos el usuario debe verificar que los valores shape y scale se encuentren completamente contenidos en el interior de los intervalos \((0,a)\) y \((0,b)\) respectivamente, de lo contrario, tendrá que modificar los valores de \(a\) y/o \(b\) y repetir el procedimiento. Lo anterior se consigue mediante una inspección visual de las variables devueltas por el ajuste: se deben ejecutar los códigos Par(B)$table$shape y Par(B)$table$scale e inspeccionar los resultados, donde B es un conjunto de datos de FRAP obtenido por medio de la función newDataFrap.
Las funciones creadas por newFit tienen el propósito de encontrar los mejores valores \(\Theta\) tales que minimicen el error cuadrático entre el modelo \(F(t|\Theta)\) y los datos reales de recuperación de la fluorescencia. Por lo que el principal criterio para elegir el modelo de probabilidad \(p\) más adecuado debe ser: preferir el modelo que produzca el menor error cuadrático medio, esto se logra, como se vio anterior mente, por medio de la función compareFit.
compareFit(B, fit=l(Exp, Gam, Wei, Par), col.lines=c("red","yellow"), lty.lines=c(2,1), lwd.lines=2, lwd.mean=2)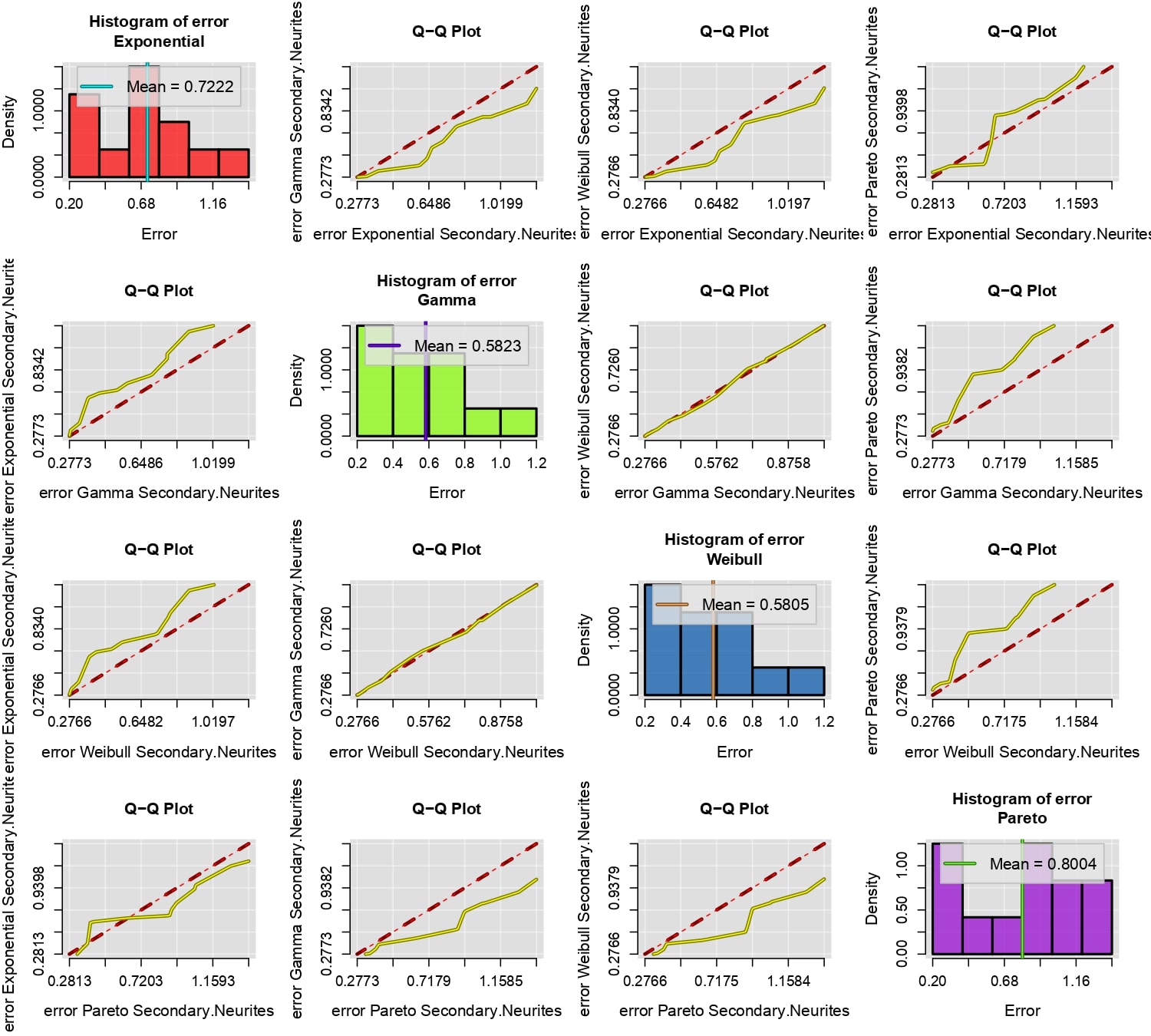
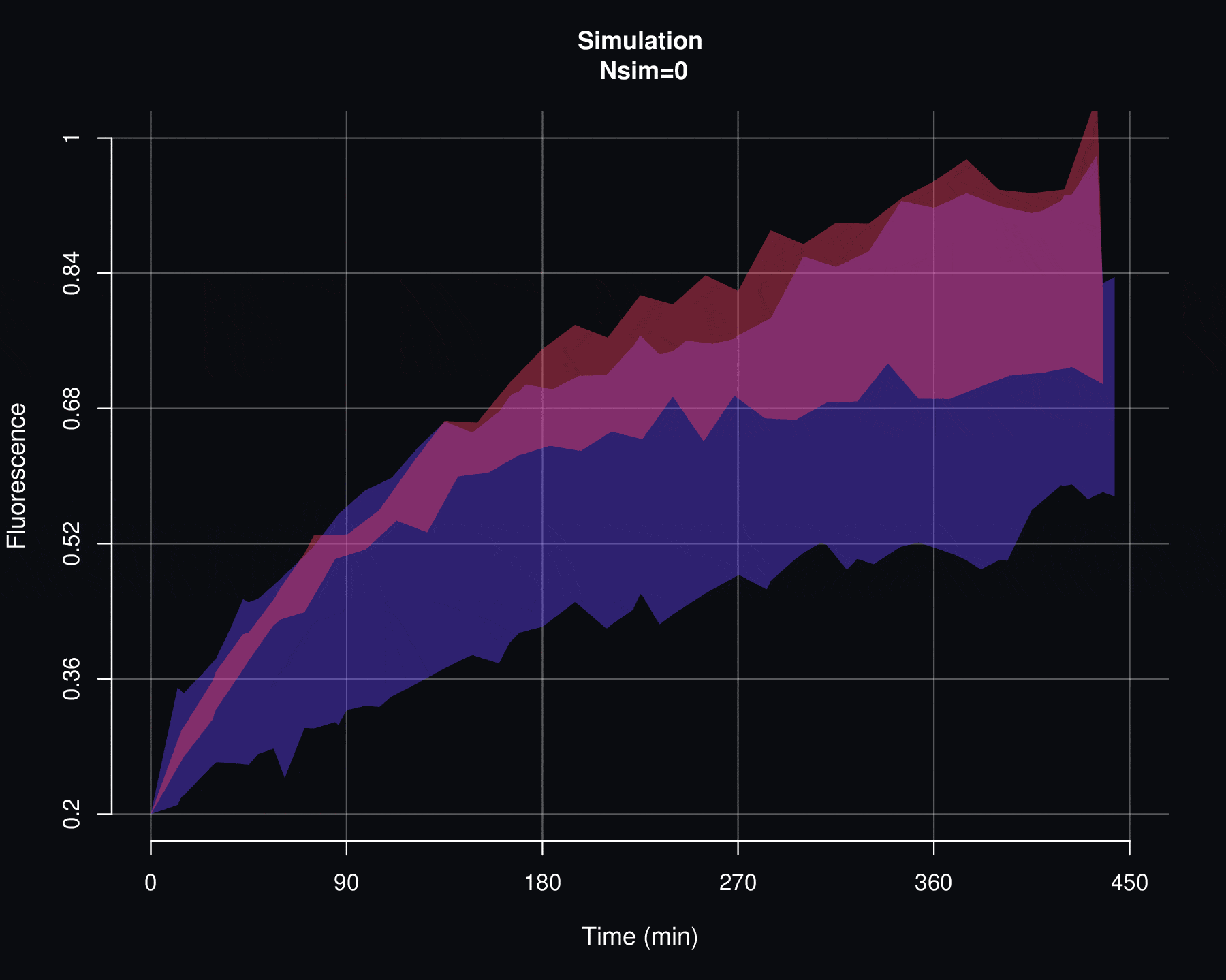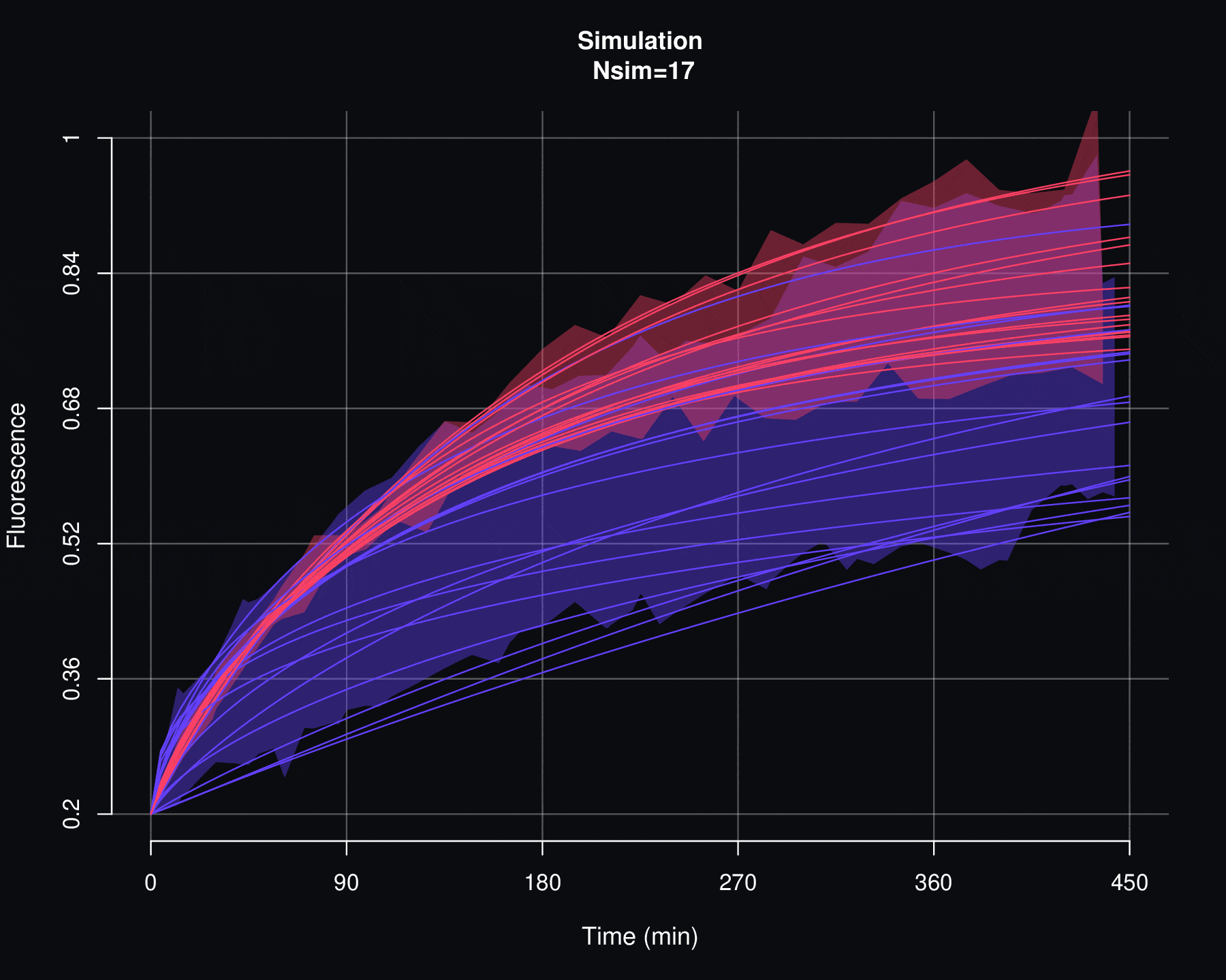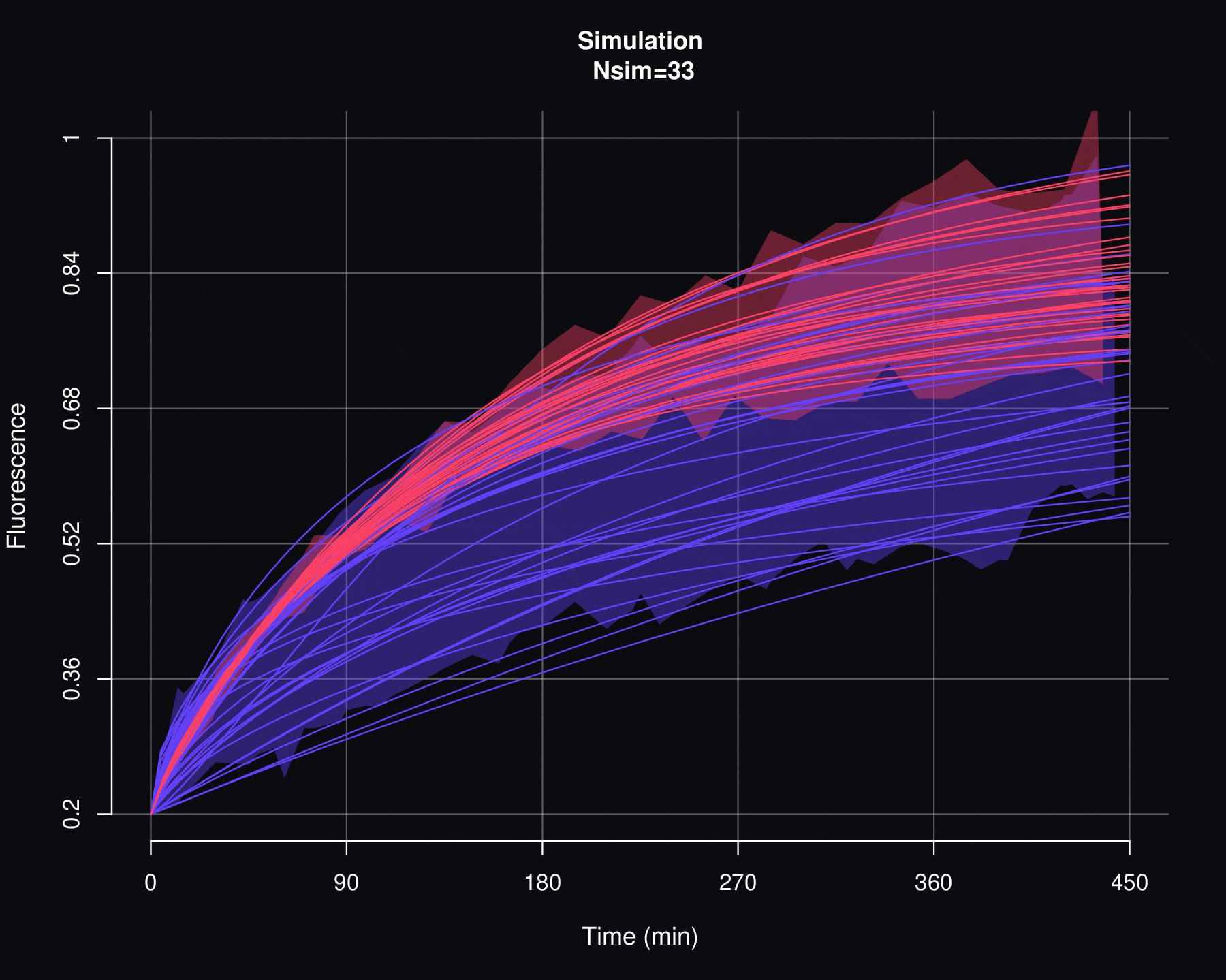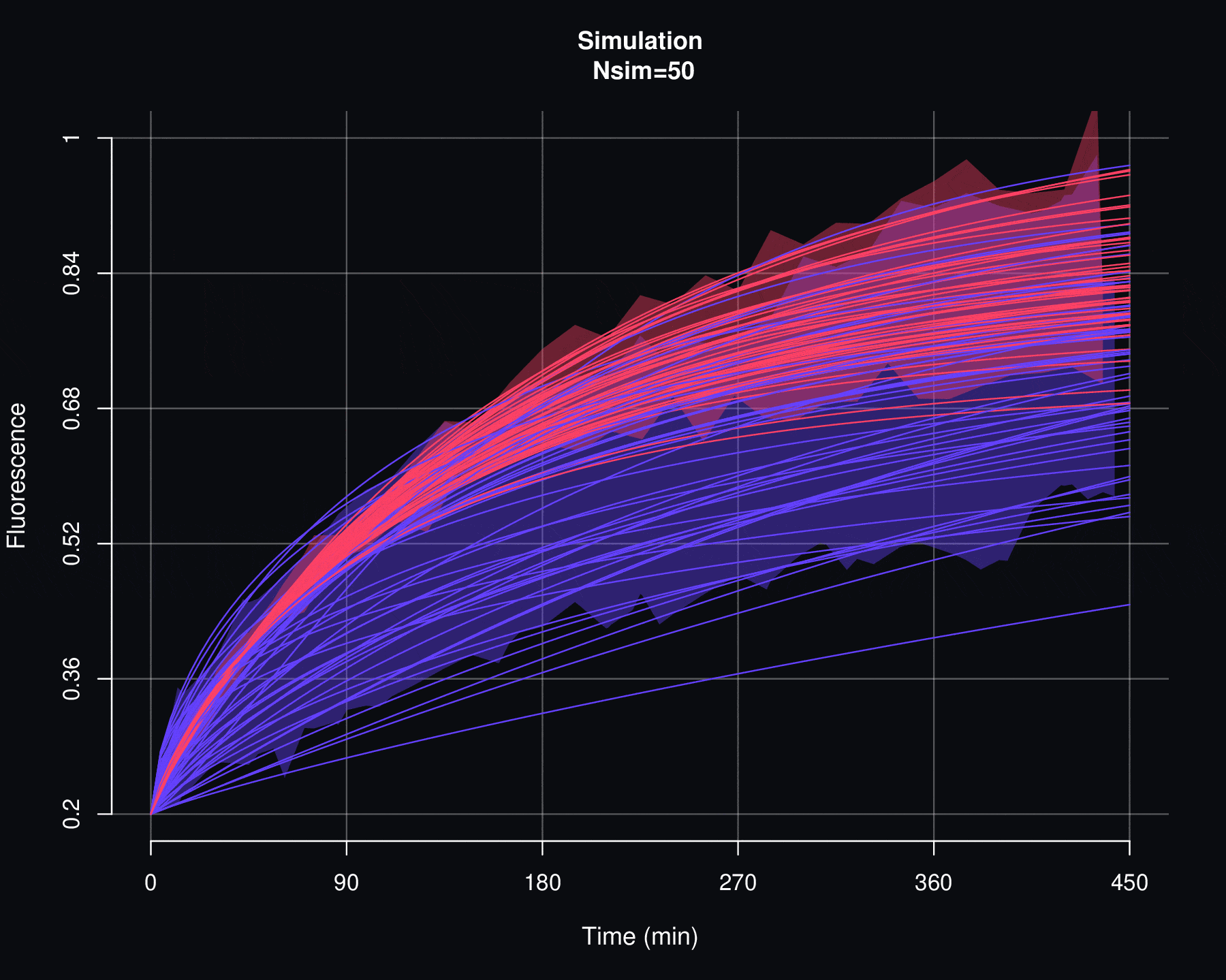
Por otro lado, un segundo criterio para evaluar la viabilidad de un modelo de probabilidad \(p\) es viendo cómo se comportan las simulaciones de \(F\). Si existen discrepancias entre los datos reales de fluorescencia y las simulaciones de \(F\) entonces lo más razonable es descartar el modelo \(p\). Ya que esto implicaría que no hay una relación causal entre los parámetros \(\Theta\) y los datos de recuperación de la fluorescencia y, como se verá en el siguiente apéndice, las simulaciones de \(f_{max}\) son particularmente sensibles a las variaciones de \(\Theta\).
plotFit(B, B, fit=l(NULL,Exp), col=c("#916F91","#FF4D66"), plot.lines=c(F,T), plot.mean=c(T,F), lwd.mean=2, plot.shadow=c(T,F), lwd.border=1, alp.border=0.4, alp.shadow=0.3, ylim=c(0.2, 1), xdigits=0, simulated=T, seed=1992, main="Exponential simulation", cex.main=1.5)
plotFit(B, B, fit=l(NULL,Gam), col=c("#916F91","#4DB34D"), plot.lines=c(F,T), plot.mean=c(T,F), lwd.mean=2, plot.shadow=c(T,F), lwd.border=1, alp.border=0.4, alp.shadow=0.3, ylim=c(0.2, 1), xdigits=0, simulated=T, seed=1992, main="Gamma simulation", cex.main=1.5)
plotFit(B, B, fit=l(NULL,Wei), col=c("#916F91","#664DFF"), plot.lines=c(F,T), plot.mean=c(T,F), lwd.mean=2, plot.shadow=c(T,F), lwd.border=1, alp.border=0.4, alp.shadow=0.3, ylim=c(0.2, 1), xdigits=0, simulated=T, seed=1992, main="Weibull simulation", cex.main=1.5)
plotFit(B, B, fit=l(NULL,Par), col=c("#916F91","#B34DB3"), plot.lines=c(F,T), plot.mean=c(T,F), lwd.mean=2, plot.shadow=c(T,F), lwd.border=1, alp.border=0.4, alp.shadow=0.3, ylim=c(0.2, 1), xdigits=0, simulated=T, seed=1992, main="Pareto simulation", cex.main=1.5)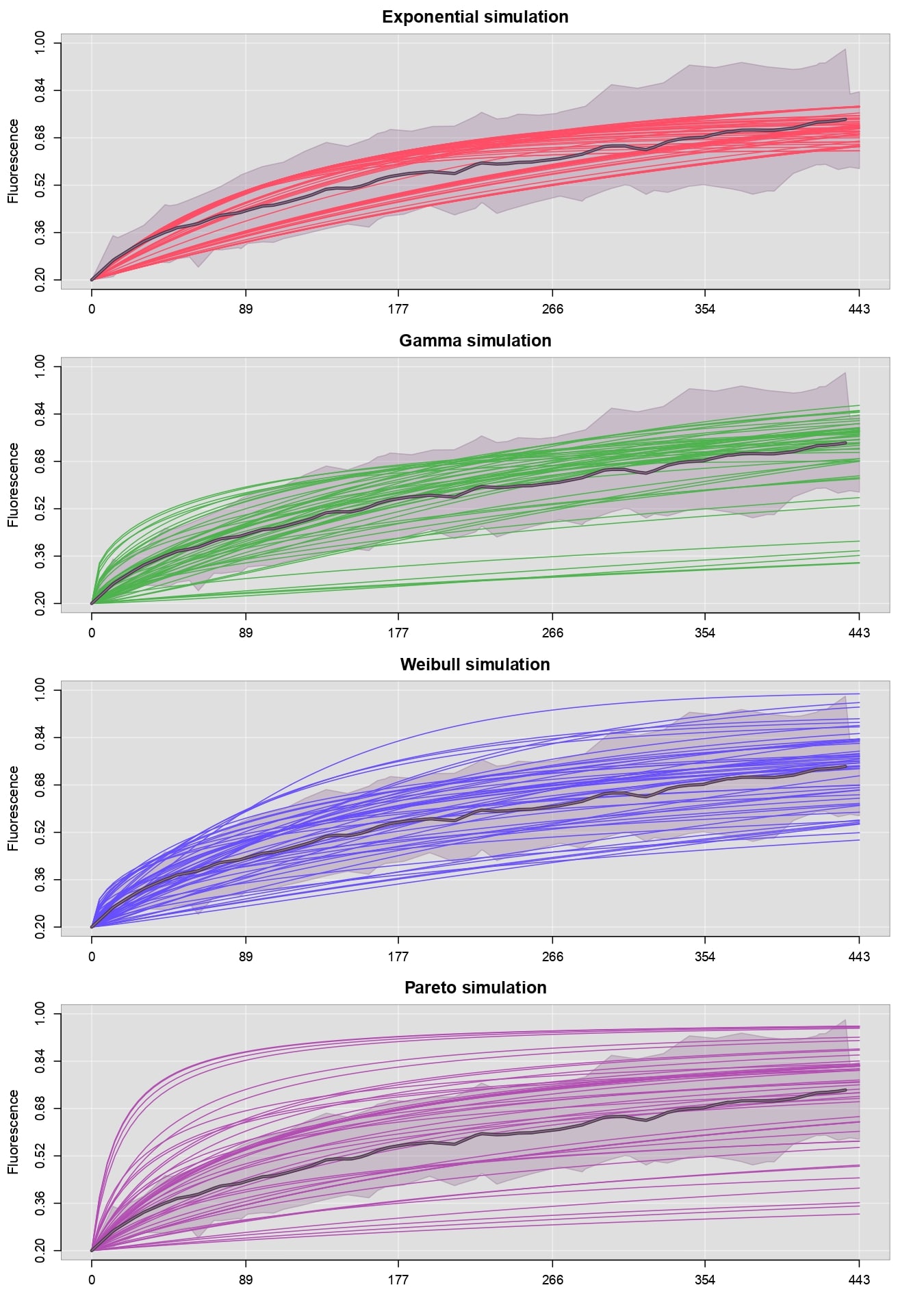
Teoría de la simulación estocástica
La simulación estocástica es un proceso mediante el cual se pretende reproducir el comportamiento de una variable aleatoria, la base de la simulación se sigue del siguiente teorema:
Sea \(X\) es una variable aleatoria y \(\mathbb F_X\) su función de distribución acumulada, sea \(U\) una variable aleatoria con distribución \(\mbox{Uniform}(0,1)\), entonces la variable aleatoria \(\mathbb F^{-1}_X(U)\) tiene la misma distribución que \(X\), es decir:
\[\mathbb F_X = \mathbb F_{\mathbb F^{-1}_X(U)}\]
Proof:
\[\begin{aligned}\mathbb F_{\mathbb F^{-1}_X(U)} &=\mathbb P\left[\mathbb F^{-1}_X(U)\leq t\right] =\mathbb P\left[\mathbb F_X\left(\mathbb F^{-1}_X(U)\right)\leq \mathbb F_X\left(t \right)\right]\\ &=\mathbb P\left[U\leq \mathbb F_X\left(t \right)\right] =\int_0^{\mathbb F_X\left(t \right)}f_U(u)\,\mbox{d}u =\int_0^{\mathbb F_X\left(t \right)}1\,\mbox{d}u\\ &=\left.u\right|_0^{\mathbb F_X\left(t \right)}={\mathbb F_X\left(t \right)}-0={\mathbb F_X\left(t \right)} \end{aligned}\] \[\therefore {\mathbb F_X\left(t \right)}=\mathbb F_{\mathbb F^{-1}_X(U)}\]
Nótese que como \(U\) es una variable uniforme, se tiene que \(f_U(u)=1,\;\; 0<u<1\). (\(f_U\) es la función de densidad de \(U\))
El teorema anterior permite simular cualquier variable aleatoria \(X\) siempre que se conozca su función de distribución acumulada \(F_X\). Sea \(\{u_1,u_2,\cdots,u_n\}\) una muestra aleatoria de valores observados de la variable aleatoria \(\mbox{Uniform}(0,1)\), entonces \(\{\mathbb F_X^{-1}(u_1),\mathbb F_X^{-1}(u_2),\cdots,\mathbb F_X^{-1}(u_n)\}\) es una muestra de valores simulados de la variable \(X\). En términos computacionales, para realizar el proceso de simulación de simulación, la generación de una muestra aleatoria uniforme se lleva a cabo por medio de algoritmos de generación de números pseudoaleatorios.
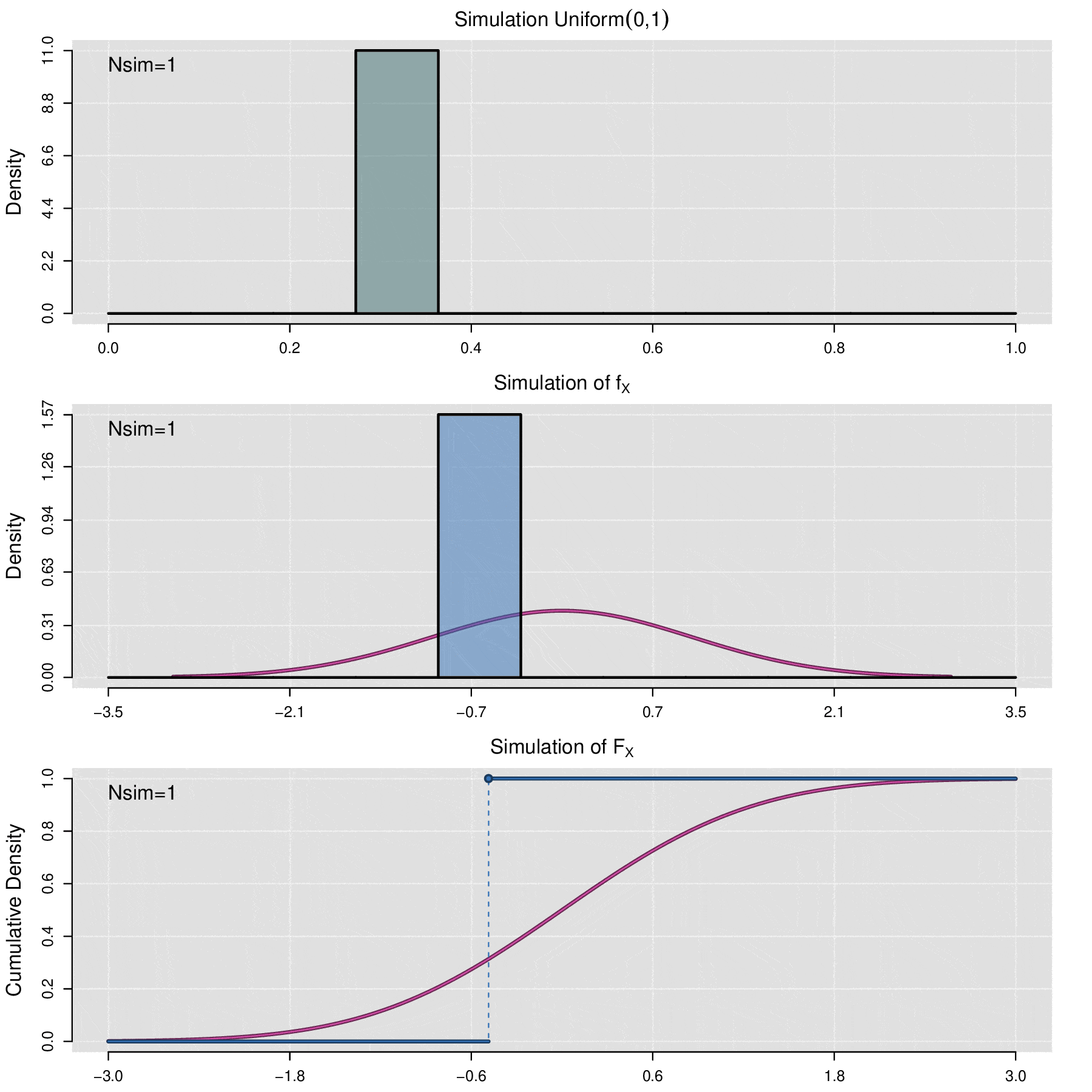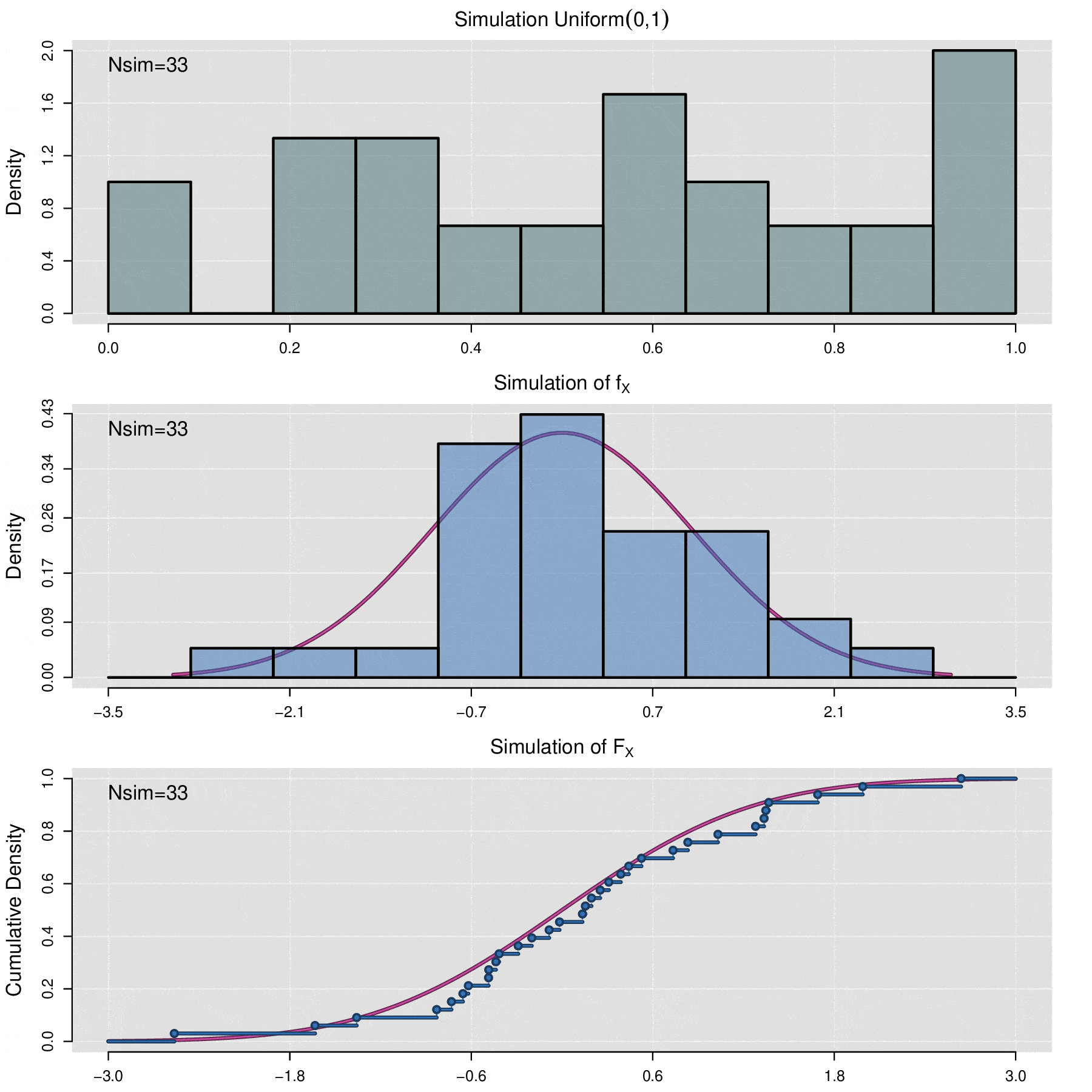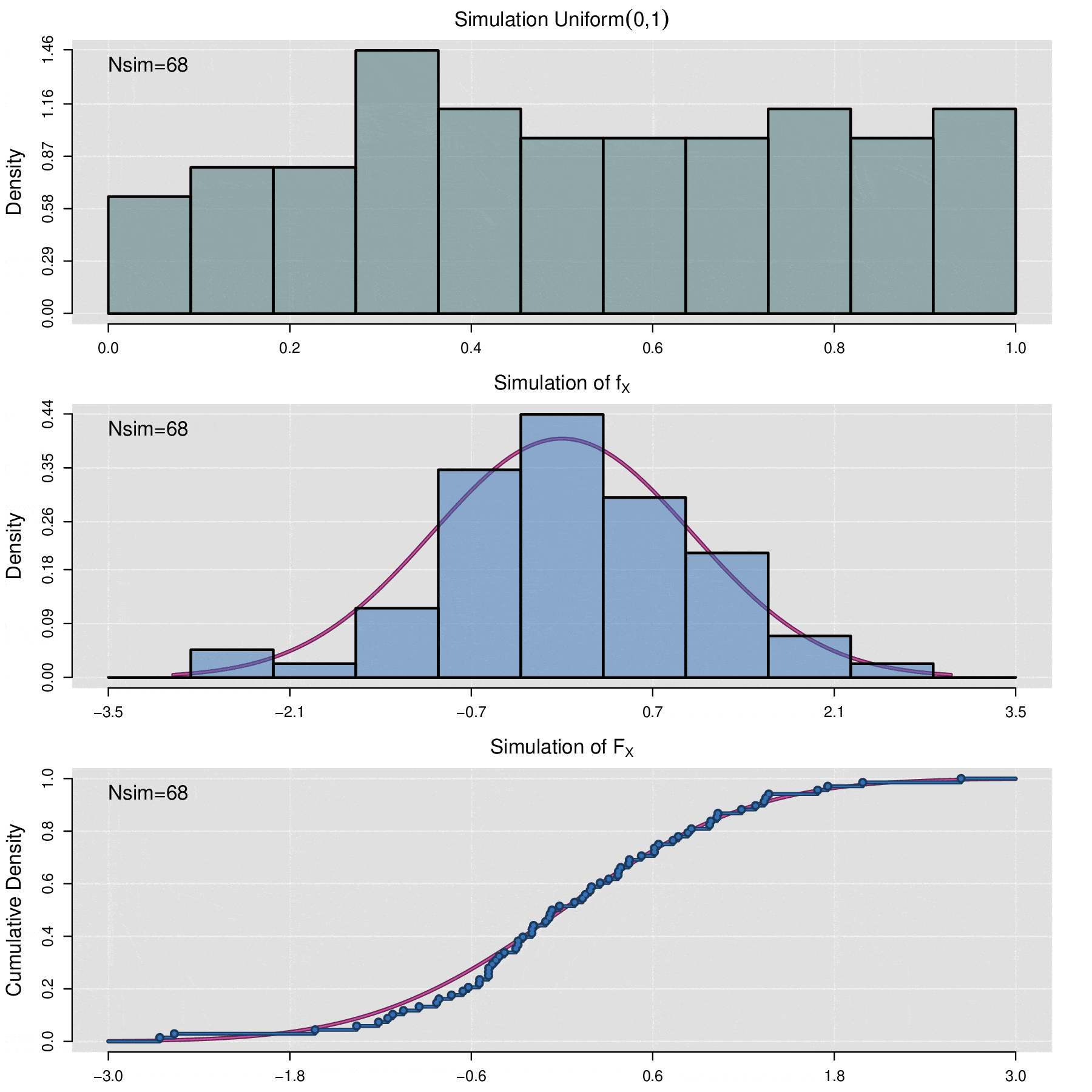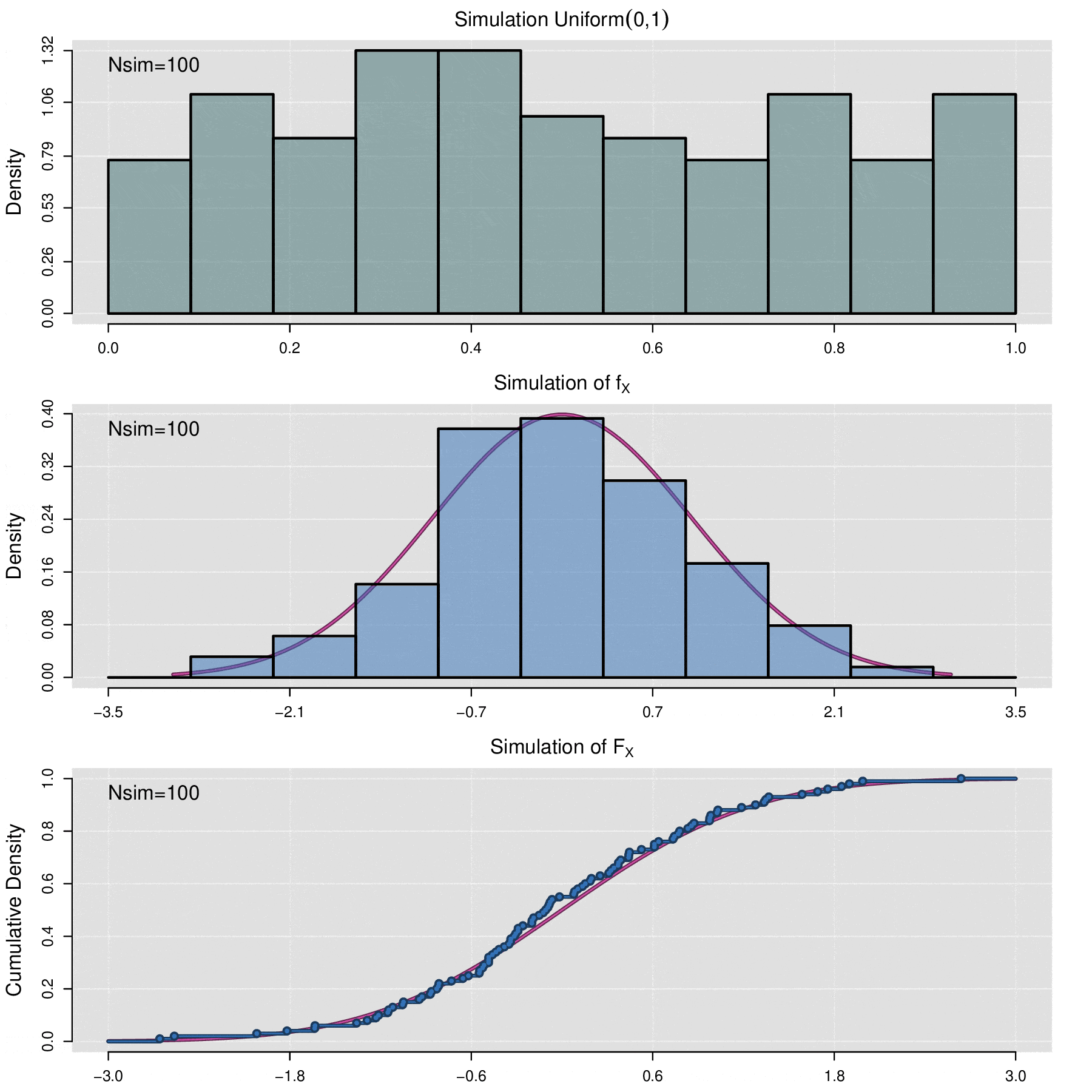
Habrá situaciones en las que se requiera simular el comportamiento de una muestra de datos \(x_1,x_2,\cdots,x_n\) de alguna distribución desconocida, por lo que no se dispone de función de distribución acumulada, en estos caso para realizar la simulación se utiliza a la función de distribución acumulada empírica (ecdf), la cual se define de la siguiente manera:
\[\widehat{\mathbb F}_{x_1,x_2,\cdots,x_n}(t)=\frac{1}{n}\sum_{i=1}^n\mathbb {I}_{x_i\leq t}\]
donde \(\mathbb{I}_{x_i\leq t}=\left\lbrace\begin{aligned} 1,\; x_i\leq t\\ 0,\; x_i> t\end{aligned}\right.\)
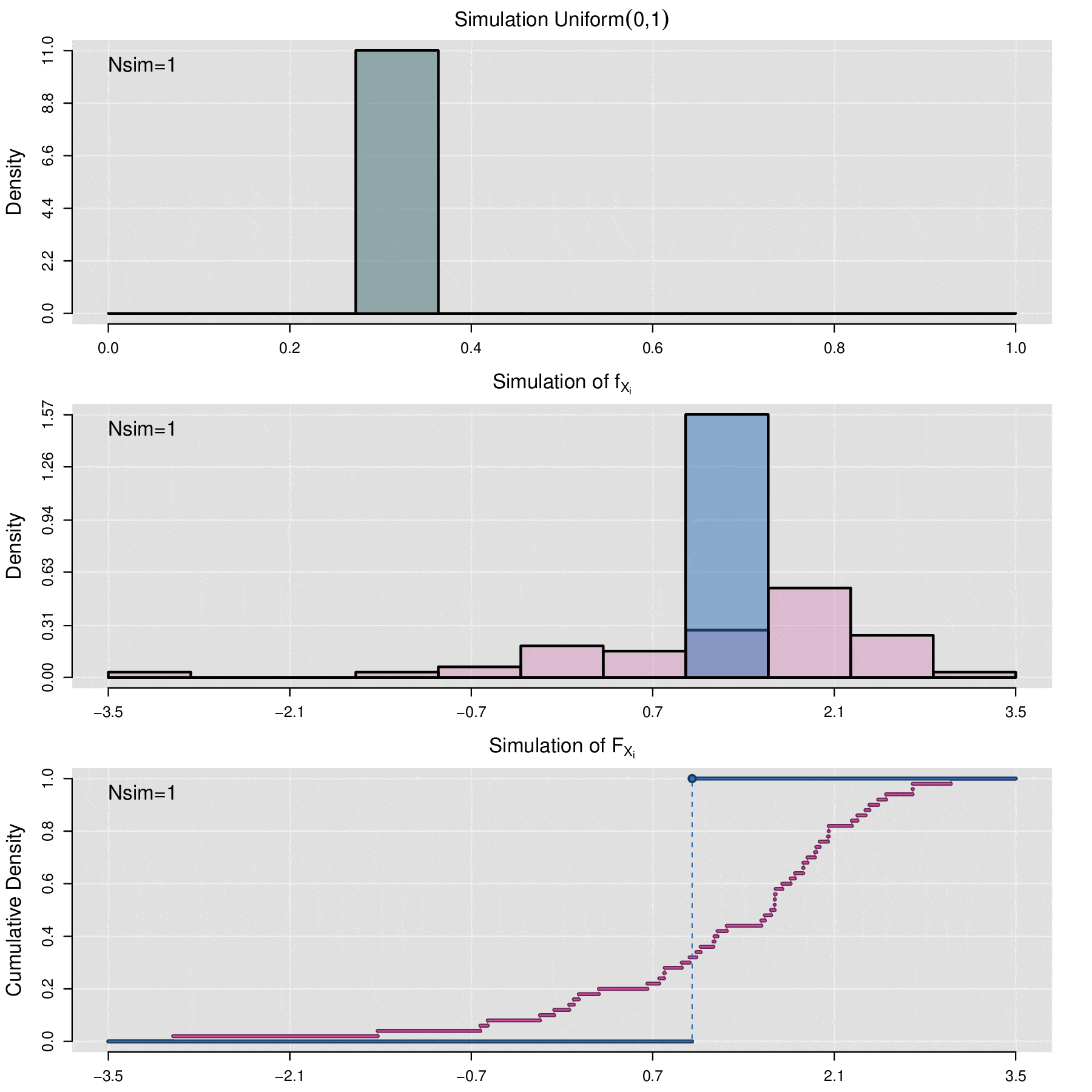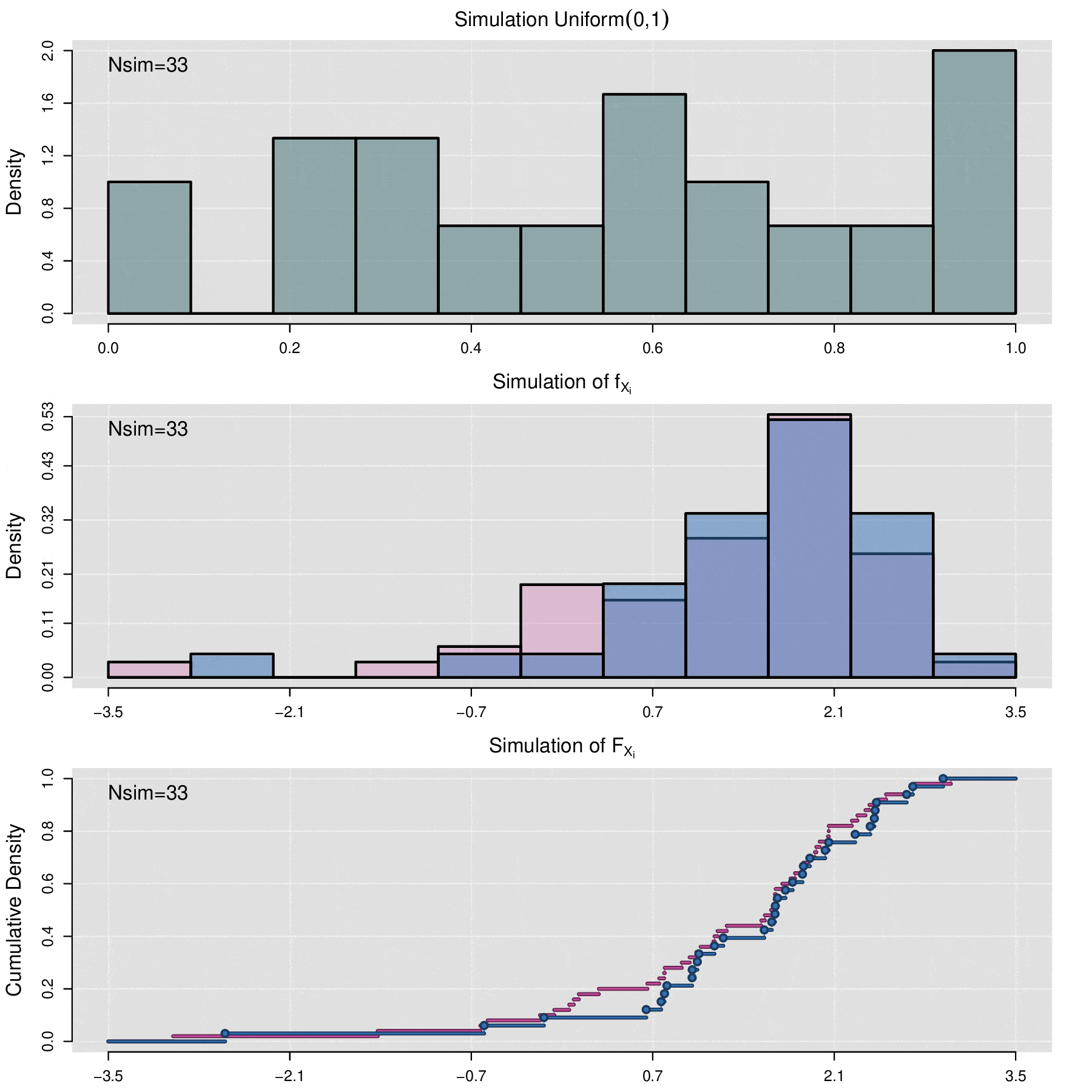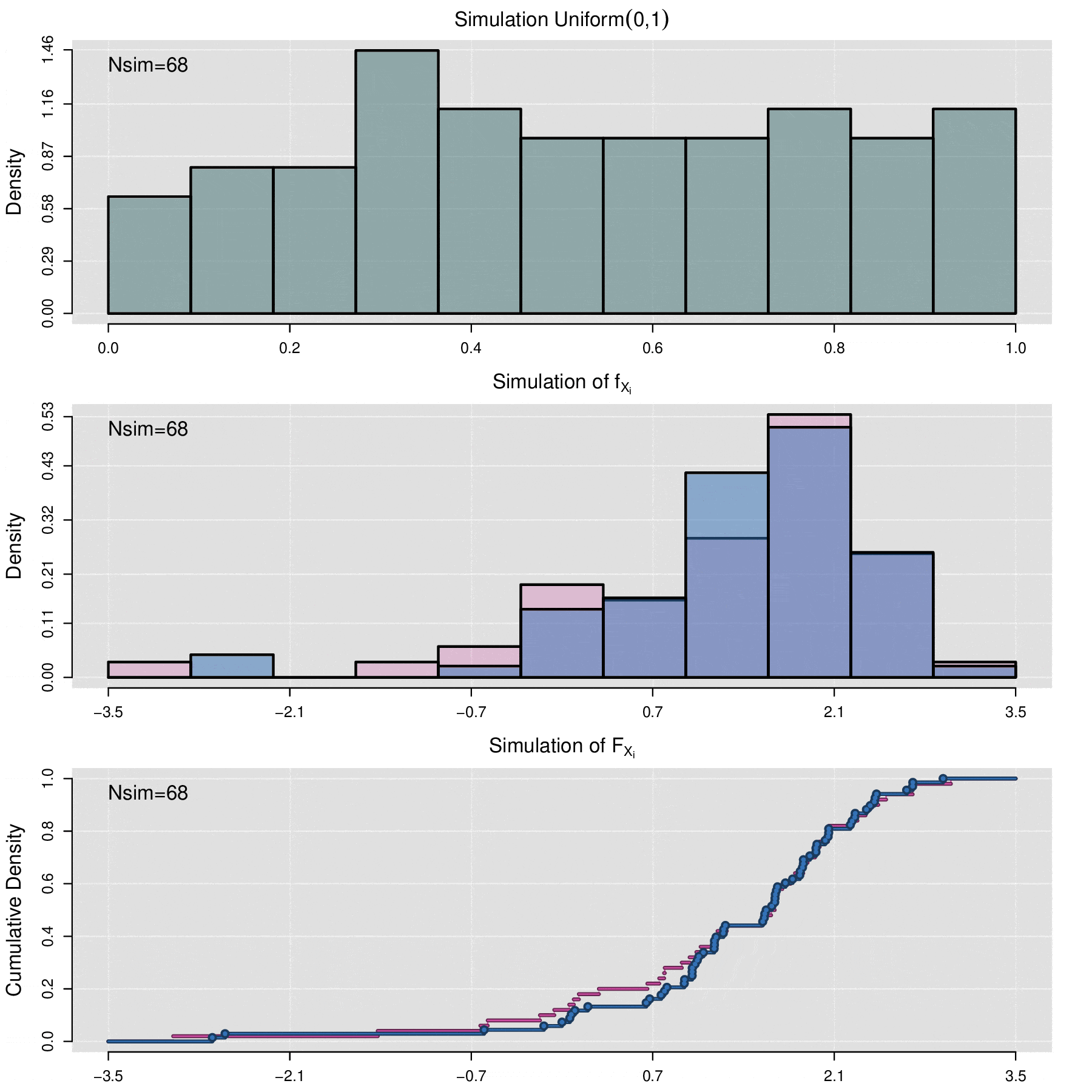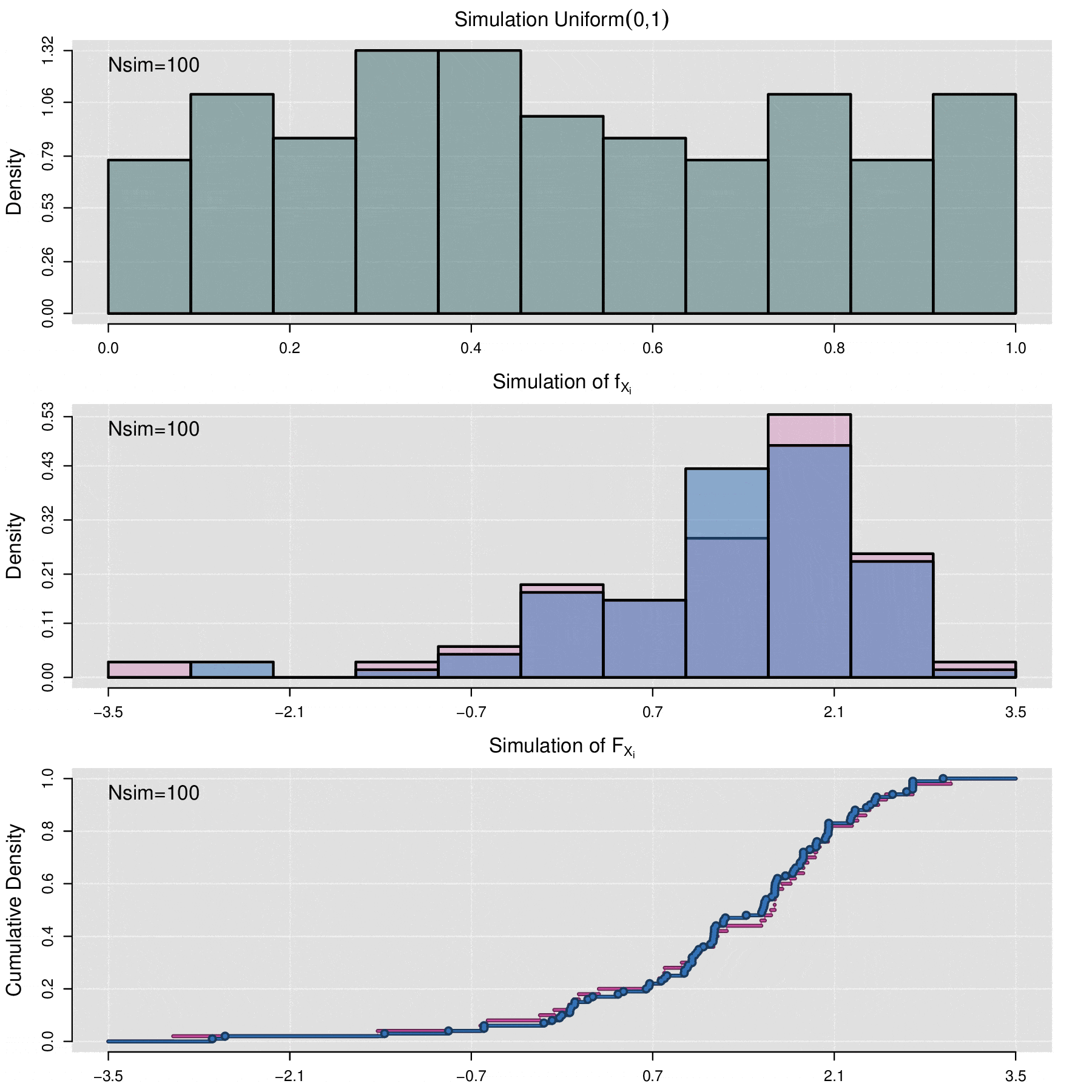
Simulación de una curva de FRAP
Cosidere el conjunto de datos de cuantificación de fluorescencia denotados por \(\{f_1,f_2,\ldots,f_n\}\) y el conjunto de curvas de FRAP asociadas \(\{F^{AB}_1,F^{AB}_2,\ldots,F^{AB}_n\}\), el proceso de simulación permite generar un conjunto de \(N_{sim}\) nuevas curvas de FRAP \(\{\mathcal F^{AB}_1,\mathcal F^{AB}_2,\ldots,\mathcal F^{AB}_{N_{sim}}\}\). Cada curva \(\mathcal F^{AB}_j\) no se encuentra directamente asociada a ningún dato de florescencia \(f_i\), en cambio, \(\mathcal F^{AB}_j\) es producto de un proceso se simulación estocastica sobre el conjunto de parámetros \(\{(\alpha_1, \Theta_1),(\alpha_2, \Theta_2),\cdots,(\alpha_n, \Theta_n)\}\), donde \((\alpha_i, \Theta_i)\) son aquellos valores que se obtuvieron por medio de la optimización por mínimos cuadrados entre \(f_i\) y \(F_i\).
De manera más específica, el proceso de simulación de las curvas de FRAP es el siguiente:
Por medio de la función de distribución acumulada empírica (vista en la sección anterior de este apéndice) de \(\{\Theta_1,\Theta_2,\cdots,\Theta_n\}\) se generan los valores \(\{ \Theta^{sim}_1,\Theta^{sim}_2,\cdots,\Theta^{sim}_m\}\), es decir:
\[\Theta_j^{sim}=\widehat{\mathbb F}_{\Theta_1,\Theta_2,\cdots,\Theta_n}^{-1}(U_j)\]
\[\mathcal F^{AB}_j(t)=f_{min}+\alpha_j^{sim}\,(1-f_{min})\,p(t|\Theta_j^{sim}).\]